最近读了杨传辉老师的《大规模分布式存储系统:原理解析与架构实战》,这本书从数据分布、负载均衡、容错、弹性伸缩等角度讨论了分布式存储系统在解决这些问题上的常见设计和实践。本文尝试从这个角度总结下 RocketMQ 和 Pulsar 两款 MQ 产品 解决这些问题时的做法。
文中的结论主要是通过阅读相关的文档(见参考)和分析源码(pulsar f9057c7, rocketMQ aaa92a2) 得出,如果错误、不准确之处欢迎各位读者指正,欢迎大家讨论交流。
分布式存储系统关注哪些问题
- 数据分布:数据如何分布、客户端请求如何路由到正确的worker 节点
- 数据同步:如何保证多副本
- 负载均衡:如何分发请求从而保证保证节点之间负载均衡
- 弹性伸缩:能否支持自动扩缩容
- 容错
- 错误感知
- 错误恢复
RocketMQ
数据模型,如下图所示
message 从属于 topic
topic 由一个或多个 Broker 负责存储
topic 内部分逻辑 queue
不考虑主备的情况下,同一个 topic 的 queue 可以分布在不同的 broker 上
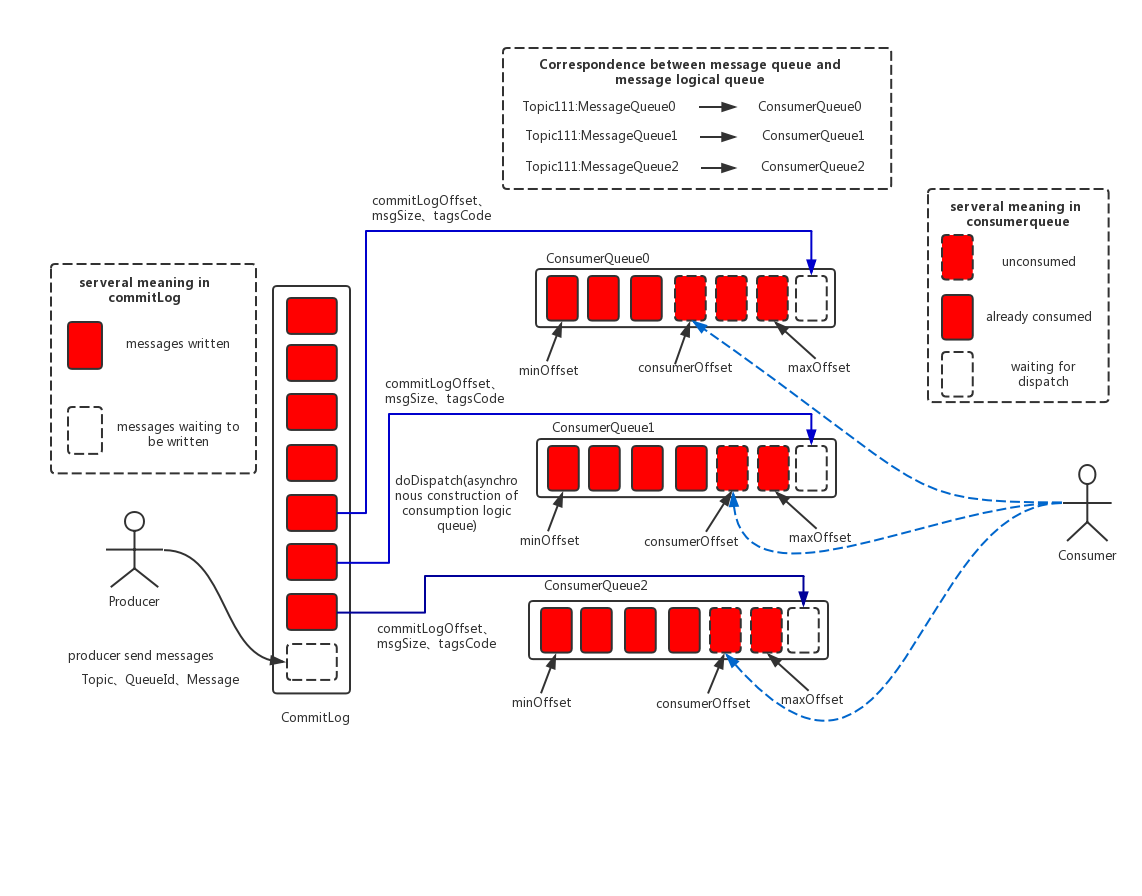
数据分布
- 按 queue 粒度进行数据分布
- 消息生产和消费的最小粒度是 queue
- 一个 queue 同时只能分给一个 consumer
- 一个 consumer 可以同时消费多个 queue
- queue 的创建和生成可以自动或人工操作,元数据存在 NameServer 中
数据同步
- HAServer: Master 上运行一个后台任务,定时向 slave 推 commit log
- Dledger:通过 raft 同步 commit log
数据路由:客户端生产或消费前,需要先从 NameServer 获取 topic 对应 Broker 的路由信息
负载均衡:不支持 queue 的动态增加、减少、分裂、合并
- 生产:如果不指定 queueId 和路由 key,RoundRobin 到备选 queue 中,即不同的 Producer 可以并发生产到同一个 queue 中
- 消费:同一个 group 的 consumer,分配所有的 queue,每个 consumer 独占一个 queue
弹性伸缩:不支持自动扩容、缩容
- 加入结点后,需要指定 master-slave 关系、指定 topic(queue)-broker 的分布关系
容错
- 错误感知
- NameServer 向 Broker 发心跳,能够感知 Broker 不可用,及时更新路由表信息
- Master Broker 定时向 Slave Broker 发心跳,能感知到 Broker 不可用
- Producer/Client 定时向所关心的所有 Broker 发心跳,能感知到 Broker 不可以
- 错误恢复
- 不支持自动的主从切换,有运维命令一键切(需要停写)
- 支持把 topic 的部分 queue 迁移到可用的 Broker 上,但是不迁移历史数据、期间可能会丢数据
- 错误感知
Pulsar
数据模型,如下图所示,这里只讨论持久化消息
message 从属于 topic
topic 下包含一个或多个 partition
partition 内部分 segment
paritition 是生产和消费的最小单位
segment 是数据迁移、多副本备份的基本单位
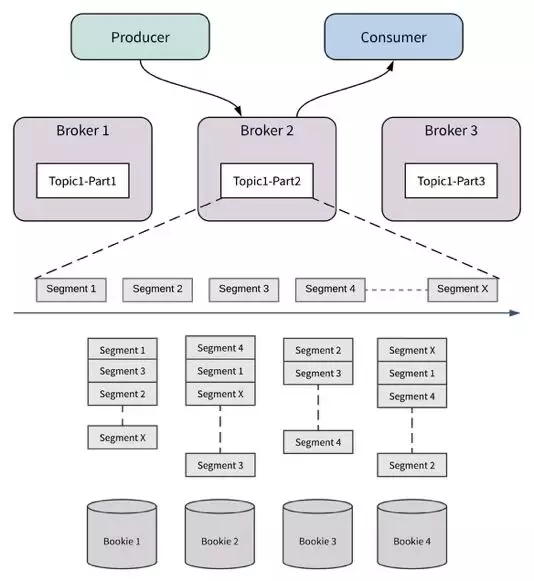
数据分布
- 不同 topic 的消息:不同 topic 的消息分散到不同的 ManagedLedger 中,在 zk 中保存了 topic 和 ManagedLedger 的映射关系
- 同一个 topic 下的消息
- 如果 topic 含有多个 partition,则每个 partition 的消息互相独立生产、存储、消费
- 同一个 partition 下的消息,分成多个 segment 存储
- 同一个 partition segment 存在一组 bookie 中
- 同一个 segment 具有多个副本,分布在同一组 bookie 中
数据同步:采用 NWR 协议进行多副本同步
- broker 写存储时,并行写 W 份
- broker 读存储时,并行读 R 份
- 同一时刻只能有一个 Broker 写存储
负载均衡
- 生产:默认情况下,RoundRobin 到该 topic 的不同 partition,即多个 Producer 可以往同一个 Paritition 并发生产消息
- 消费:同一个 Subscription 下的 Consumer 之间进行所以 partition 的负载均衡
- 一个 paritition 可以同时(在 Shared 订阅模式下)被多个 Consumer 消费,一个 consumer 也可以同时订阅同一个 topic 下的多个 partition,即 partition 和 consumer 的关系是 M-to-N
- 同一个 paritition 能服务的 consumer 数量可以由配置项控制
弹性伸缩:计算层(broker)和存储层(Bookkeeper)可以独立弹性伸缩
- 计算层:一个 topic 只能由一个 broker 读写,因此如果计算能力跟不上,可以通过加计算节点的方式让 topic 分配到新增的 broker 上,减轻单个 broker 上的负载压力,实现 topic 粒度的负载均衡
- 存储层:整个存储集群是一个 bookie 池,增加存储节点记为增加池子的负载上限
容错
- 每条消息生产时被复制到多个 bookie 节点上,并且由存储集群保证可用副本数
- 如果 bookie 节点故障,存储集群可以自动做数据迁移,保证可用副本数
- 如果 NWR 参数有调整,存储集群自动从老街店复制数据副本
- 计算层无状态,如果 broker 故障,则会将该 broker 上的 topic 迁移到其他 broker 上
- 迁移过程只是 topic-broker 映射关系元数据的变更,不迁移数据
- broker 故障转移时需要 fencing
- 存储层:Bookkeeper 集群能保证 N 的数量,即读写备选结点数量,如果有备选结点故障会从集群中挑选可用结点替换故障结点
- 每条消息生产时被复制到多个 bookie 节点上,并且由存储集群保证可用副本数
参考
- RocketMQ 设计文档 https://github.com/apache/rocketmq/blob/master/docs/cn/design.md
- 「分布式系统前沿技术」专题 | Pulsar 的设计哲学 https://mp.weixin.qq.com/s/13sd3aR0LdkG-H6094r_Iw
- Apache BookKeeper 简介 https://mp.weixin.qq.com/s/BOuF5_MAzw77kPsN9BbCcg
- Pulsar 的消息存储机制和 Bookie 的 GC 机制原理 https://mp.weixin.qq.com/s/3jmExKsfPVJo9NLzekMKxQ

