- 列存的目的
- 表格模型:每个表格由很多行组成,通过主键唯一标识,每一行包含很多列
(row:string, column:string, timestamp:int64) -> string - Bigtable
- 列族 column family:包含多个列,是 Bigtable 中访问控制的基本单元
- 在创建表格时要预先定义好,数量不能过多
- 列族中包含哪些 qualifier 不需要你预先定义,数量可以任意多
- 行主键:任意字符串,不超过 64KB
- 存储格式

- 架构
- 表格类型
- User Table:存储用户实际数据
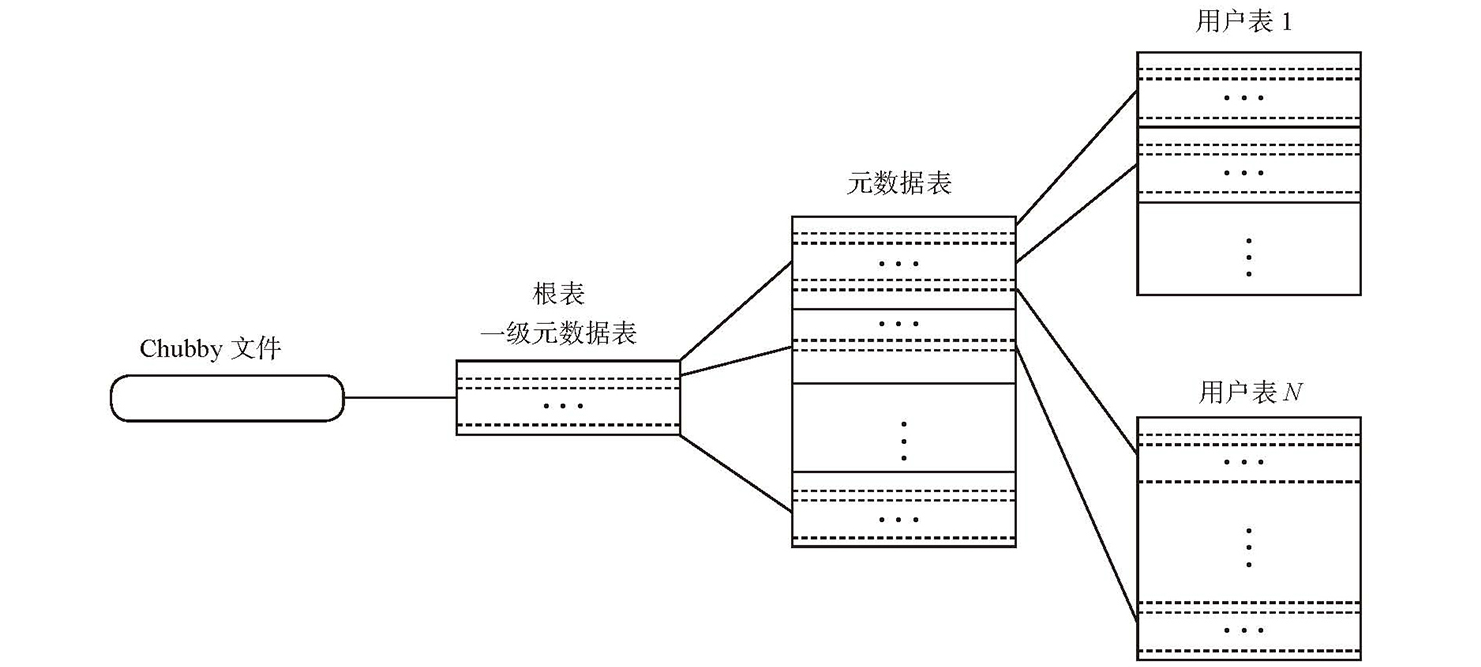
- Meta Table:用户表元数据,包括
- 子表位置信息
- SSTable 及操作日志文件编号
- 日志回放点
- Root Table:存储 Meta Table 的元数据,又称为 Bigtable 引导信息
- 数据结构示意图
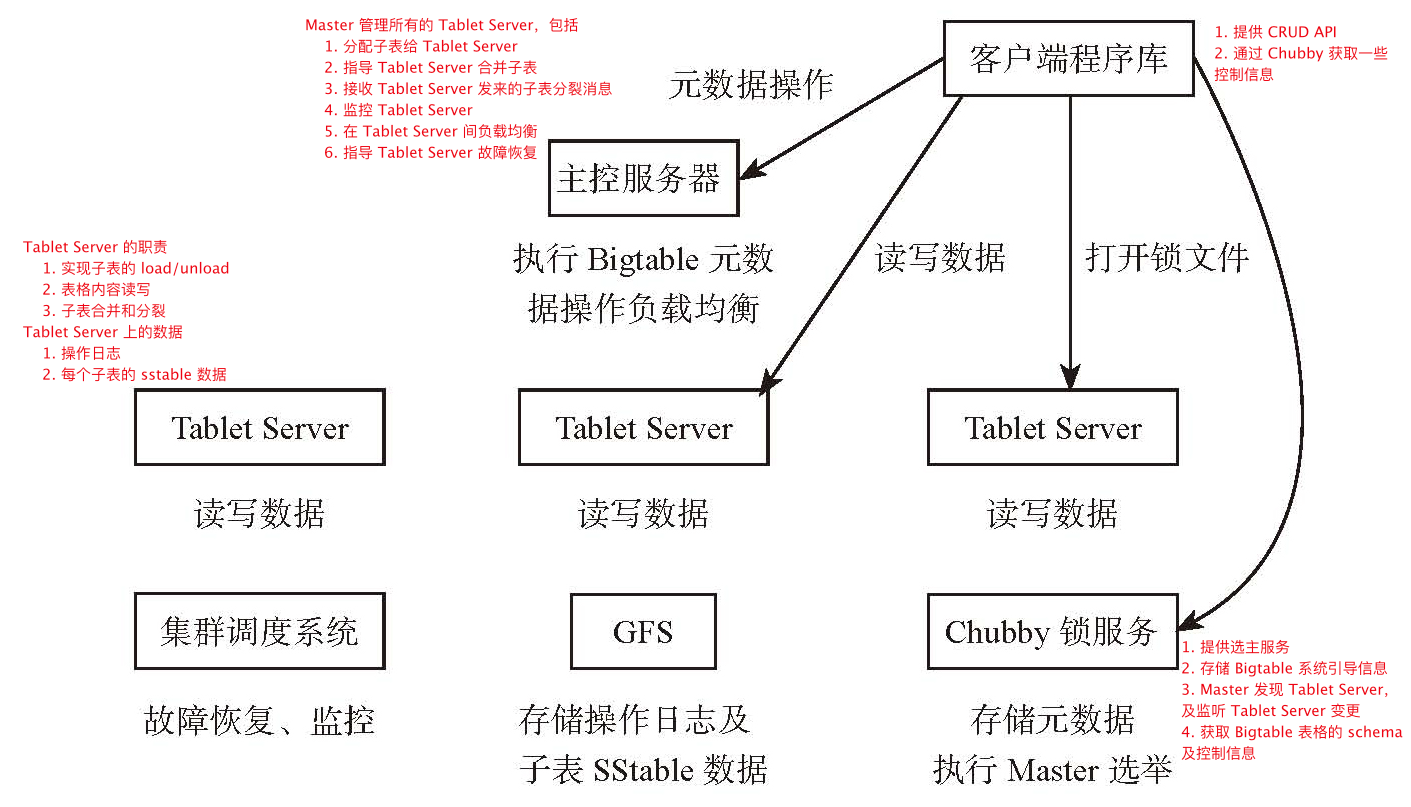
- 一致性:通过同一时刻只有一个 Tablet Server 维护一个子表保证强一致性
- Master 通过 Chubby 锁服务保证只有一个 Tablet Server 维护一个子表
- 容错
- Tablet Server 初始化时,从 Chubby 中获取一个独占锁
- Master 定时询问 Tablet Server 独占锁的状态,如果锁丢失或没有响应则 Master 自己尝试获取独占锁,来判断是 Chubby 的问题还是 Tablet Server 的问题,如果 Tablet Server 的问题则将其子表迁移到其他 Tablet Server
- 所有子表的操作日志写在一个文件中,通过
<table_id, row_key, sequenceId>来唯一标识
- 负载均衡:子表是负载均衡的基本单位
- Tablet Server 定期向 Master 汇报状态
- Master 检测到某个 Tablet Server 负载过高时,会进行自动负载均衡,即子表迁移
- 请求原有的 Tablet Server 卸载子表
- 请求新的 Tablet Server 加载子表(需要先获取互斥锁)
- 负载均衡期间有短暂的时间需要停服务,Bigtable 通过两次 Minor Compaction 减少停服务时间
- 原有 Tablet Server 对子表执行一次 Minor Compaction,期间允许写操作
- 停止子表的写服务,对子表再执行一次 Minor Compaction
- 子表分裂与合并
- 分裂:将内存中的索引信息分成两份分裂前的子表在同一个 Tablet Server 上不需要拷贝数据
- 分裂操作由 Tablet Server 发起,需要修改元数据,修改元数据成功即算分裂操作成功,分裂成功后向 Master 汇报
- 元数据表的分裂需要修改 Root 表
- Tablet Server 加载子表过程中如果发现子表已分裂,需要汇报 Master,
- 合并:将多个子表合并成一个子表,由 Master 发起
- 需要拷贝数据
- 分裂:将内存中的索引信息分成两份分裂前的子表在同一个 Tablet Server 上不需要拷贝数据
- 列族 column family:包含多个列,是 Bigtable 中访问控制的基本单元
- 单机存储
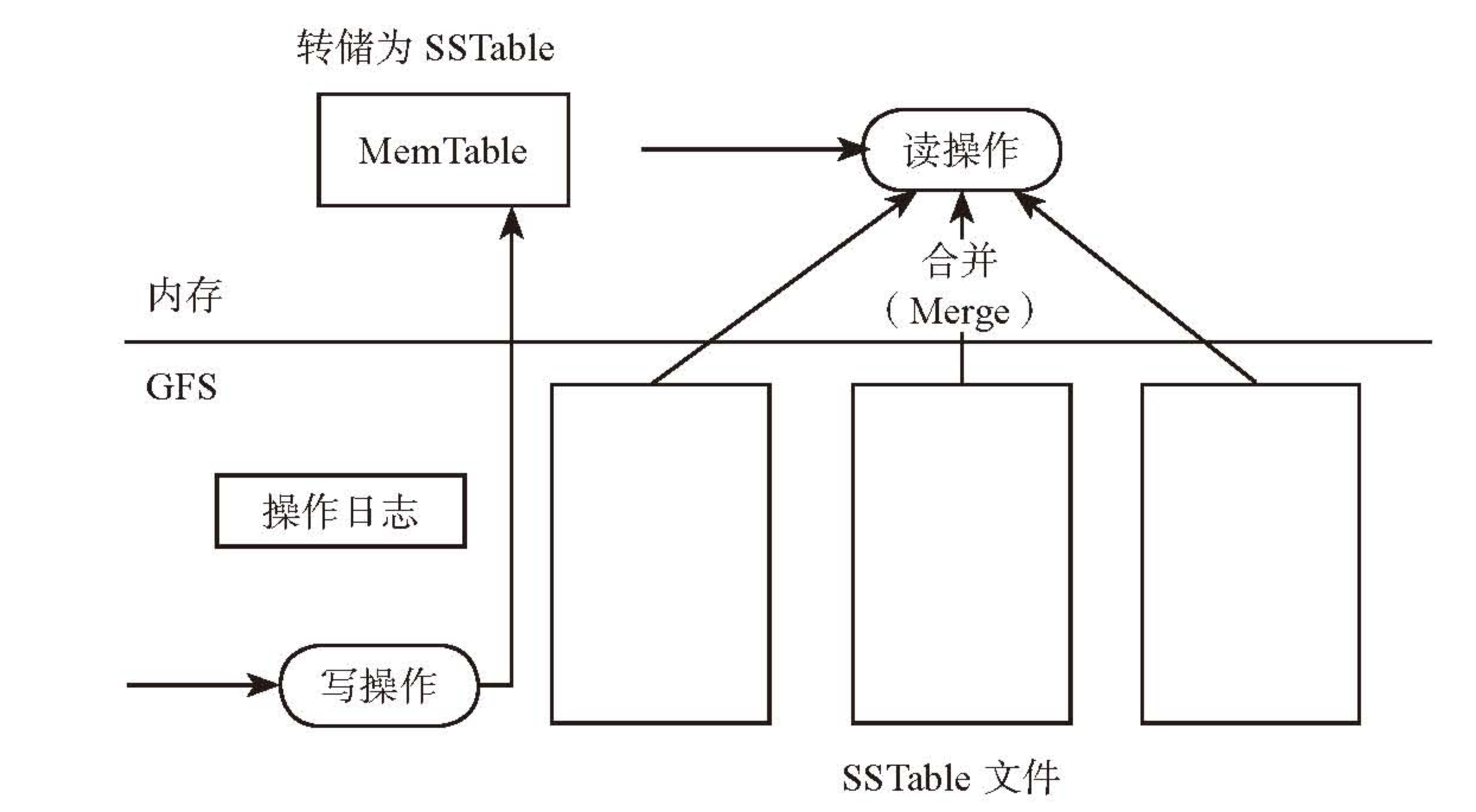
- Compaction
- Minor Compaction: MemTable dump 成 SSTable,减少内存占用
- Major Compaction:合并多个 SSTable 和 MemTable 生成一个更大的 SSTable
- Merge Compaction:合并多个 SSTable,生成 SSTable 过程中会有删除、增加操作
- Compaction
- Bigtable 面临的问题
- 单副本服务,适合离线和半线上业务,不适合实时业务
- 不能完美适应 SDD
- 架构复杂导致难以定位 bug
Google Megastore
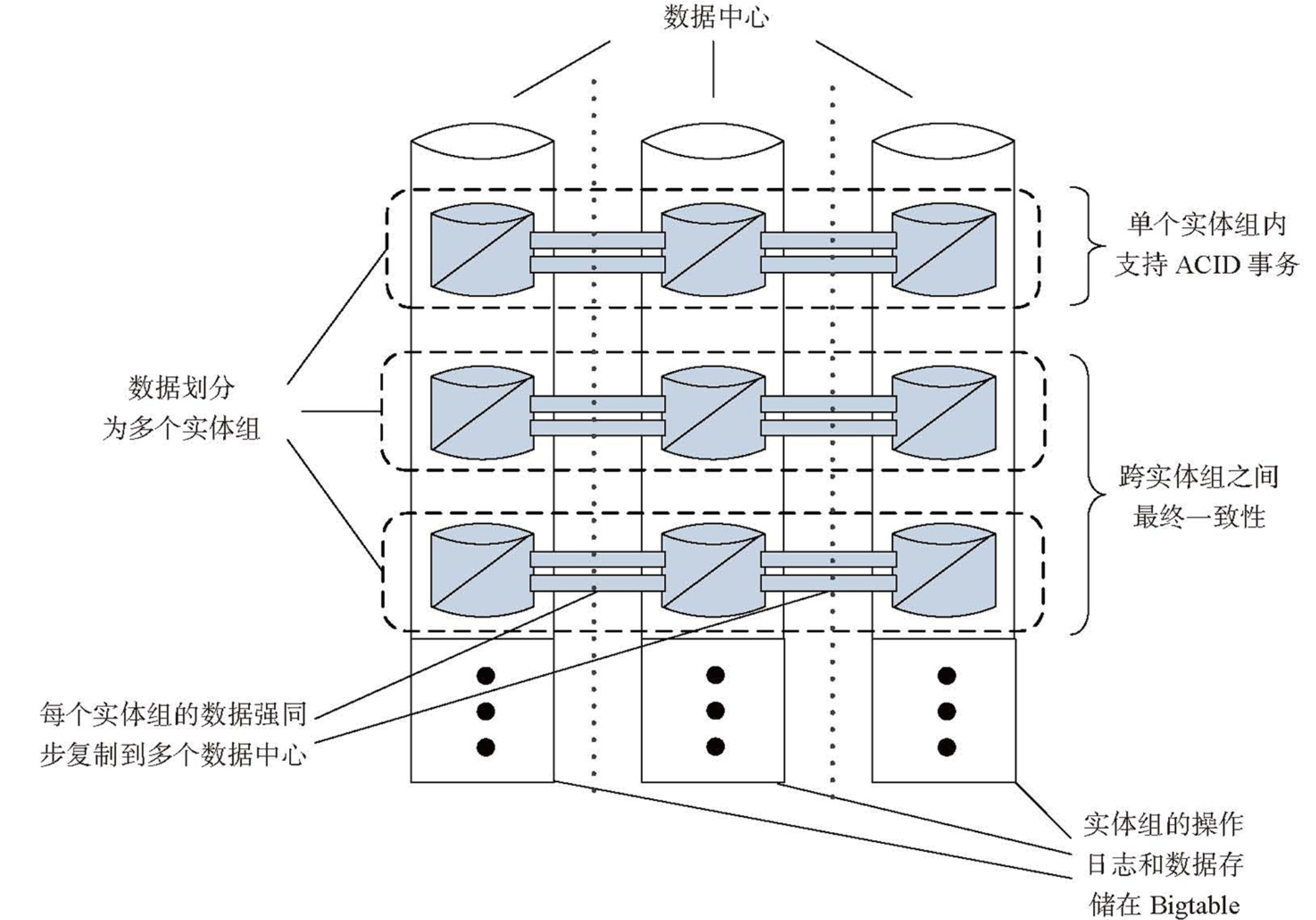
- 实体组:将相关的实体进行分组管理,实现扩展性和数据库语义之间的权衡
- 背景原因:同一个用户的内部操作要求强一致性,多个用户之间的操作要求最终一致性,因此可以根据用户将数据拆成不同的分组
- 做法:例如存在 User 表和 Photo 表,其中 User 作为实体组根表 ,Photo 为实体组子表
- 实体组根表中的一行称为一个根实体(Root Entity),存放用户数据及 Megastore 事务及复制操作所需的元数据,例如操作日志
- Bigtable 通过单行事务保证根实体操作的原子性,即同一个实体组的元数据的原子性
- 向实体组写入数据时,需要先向根实体组写入操作日志,再重放操作日志
- Megastore 架构 https://weread.qq.com/web/reader/2fa32a80597ca72fa76b61fkd3d322001ad3d9446802347
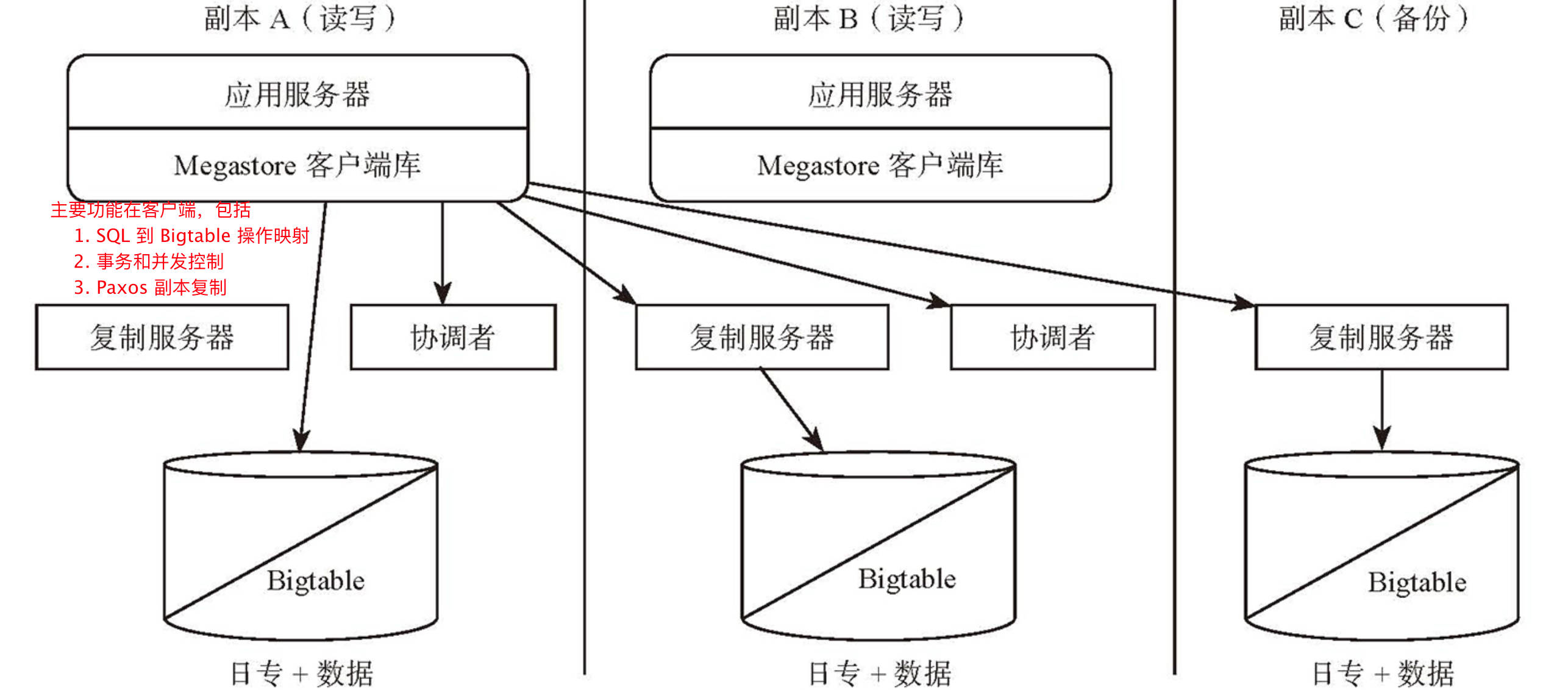
- 实体组
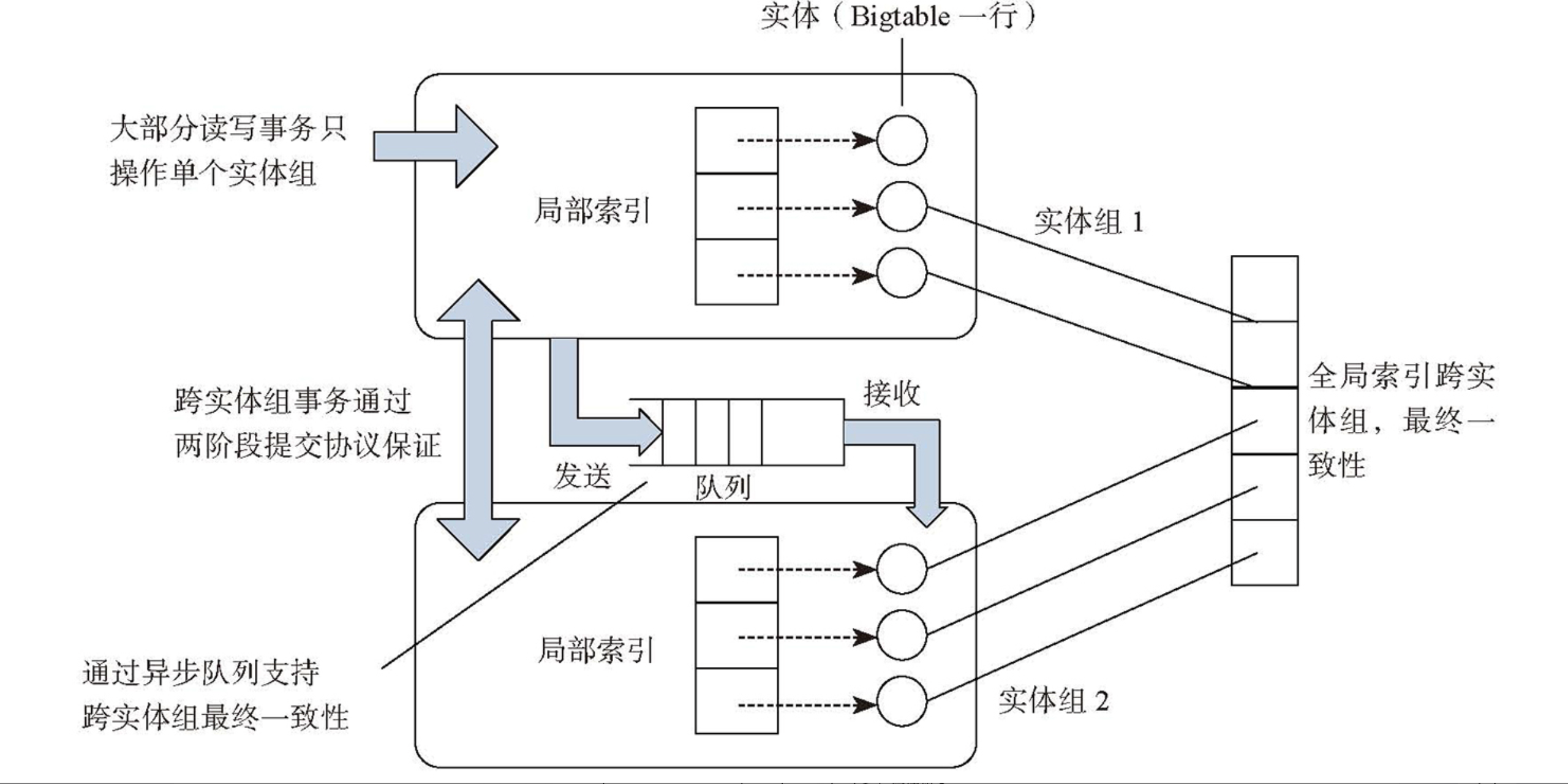
- 单实体组通过 REDO 日志实现事务,写 REDO 日志成功则操作成功,读最新版本之前需要重放 REDO 日志
- 跨实体组通过分布式队列实现最终一致性,发送跨实体组的操作到目标实体组
- 并发控制:可串行化隔离级别
- 读事务
- 最新读(Current Read):读之前需要保证所有写操作已全部生效,然后读取最后一个版本的数据,针对单实体组
- 快照读(Snapshot Read):读已知最后一个完整提交的事务版本的数据,针对单实体组
- 非一致性读(Inconsistent Read):直接读 Bigtable 内存中的值,而不管日志的状态,可能读到不完整的数据,针对多个实体组
- 写事务:采用预写日志,所有操作都在日志中记录后才会修改数据状态

- 读事务
- 索引
- 局部索引:属于单个实体组,加速实体组内部查询,原子更新
- 全局索引:跨实体组
- 协调者
- 快速读
- 原理:Paxos 要求读取的数据至少需要一半以上的副本,而没有故障时,每个副本都是最新的,因此可以使用本地读减少读取延迟和跨机房操作
- Megastore 引入协调者记录本机房每个实体组的数据是否最新,从而支持实现快速读
- 写操作需要将协调者记录的实体组状态失效,如果写入失败,需要先将协调者记录的实体组状态失效后才能返回
- 协调者可用性
- 协调者启动时,获取 Chubby 锁服务
- 协调者处理请求时,需要先获取 Chubby 锁,如果锁失效,则协调者会进入默认保守状态
- 协调者不可用到锁失效会有几十秒的过期时间,在此期间所有写操作都会失败
- 竞争条件
- 协调者收到的网络消息可能乱序,因此每条生效和失效消息中都带了日志的位置信息,如果先收到较晚的失效操作,后收到较早的生效操作,则较早的生效操作会被忽略
- 协调者从启动到退出为一个生命周期,每个生命周期用一个唯一序号标识,生效操作只允许在最近一次对协调者读取操作以来序号没发生变化的情况下修改协调者状态
- 快速读
- 读取流程
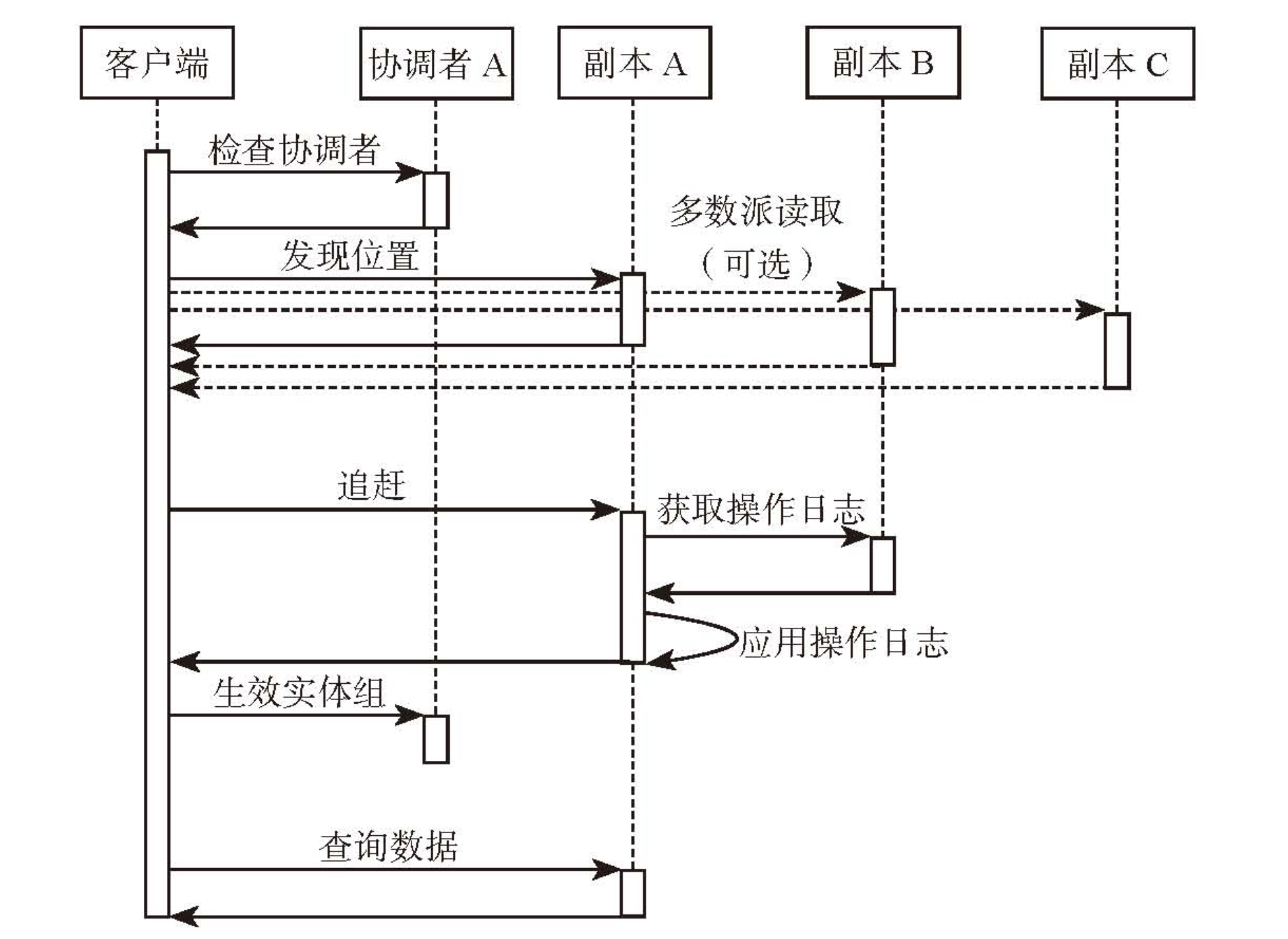

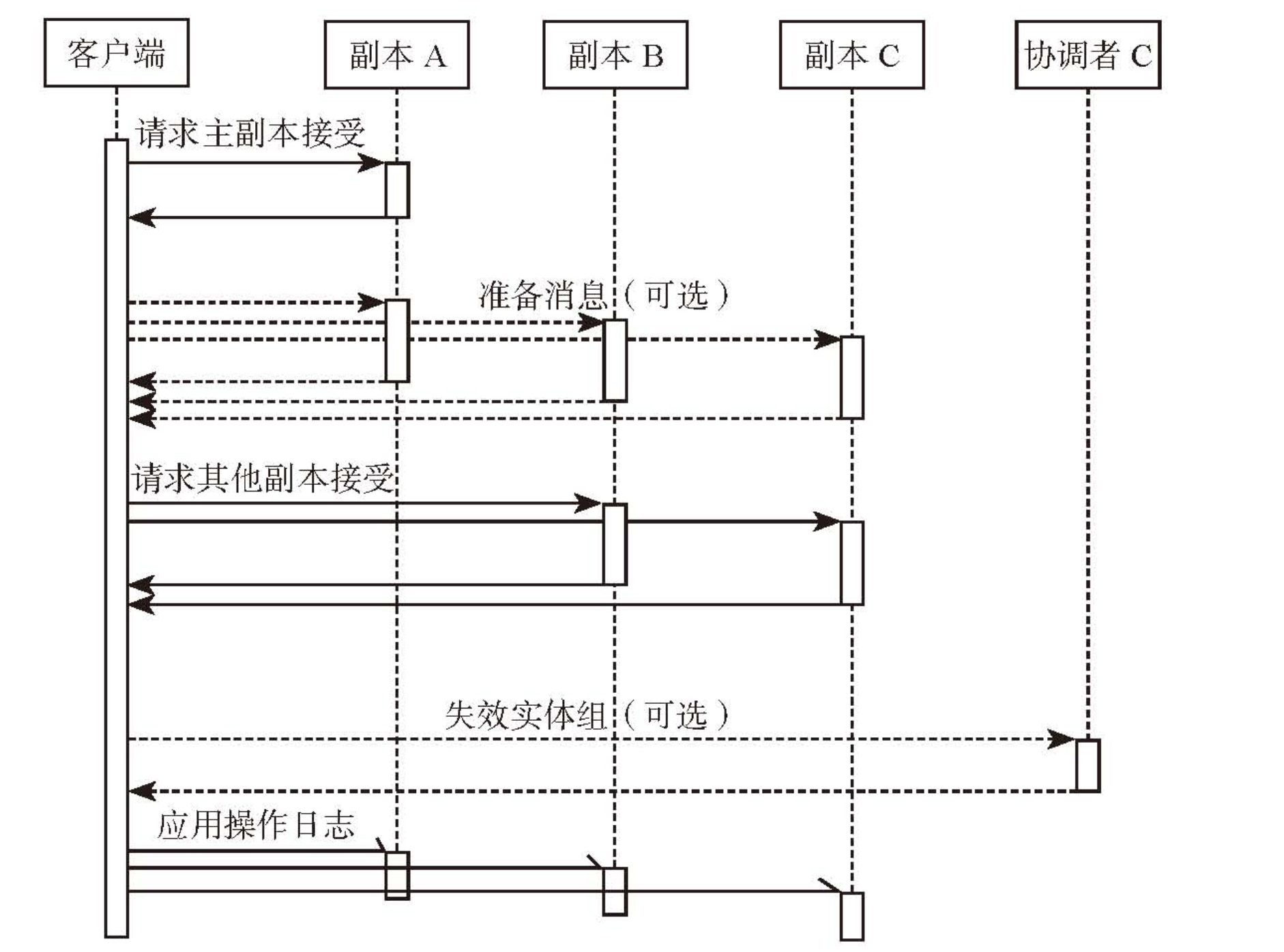
- 写入流程


Windows Azure Storage(WAS)
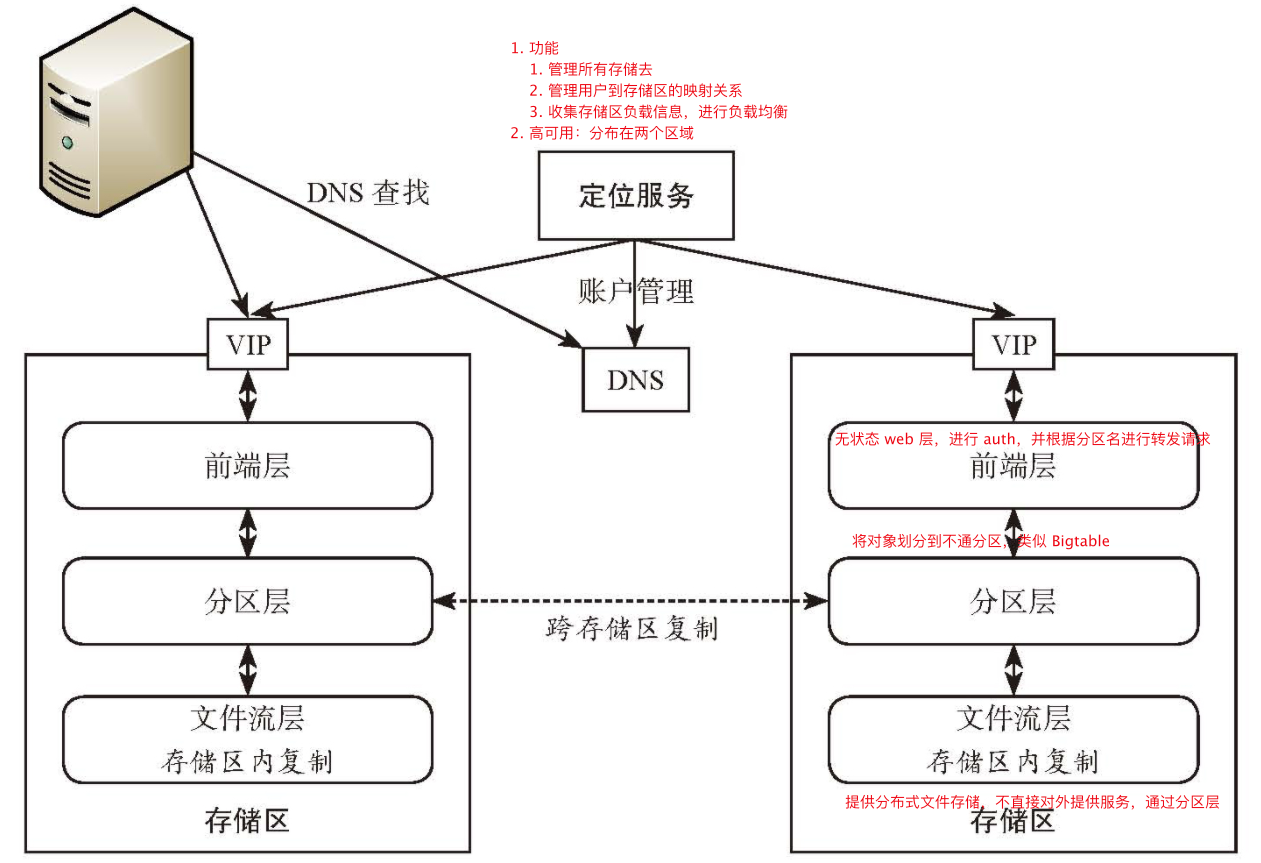
- WAS 架构
- WAS 复制方式
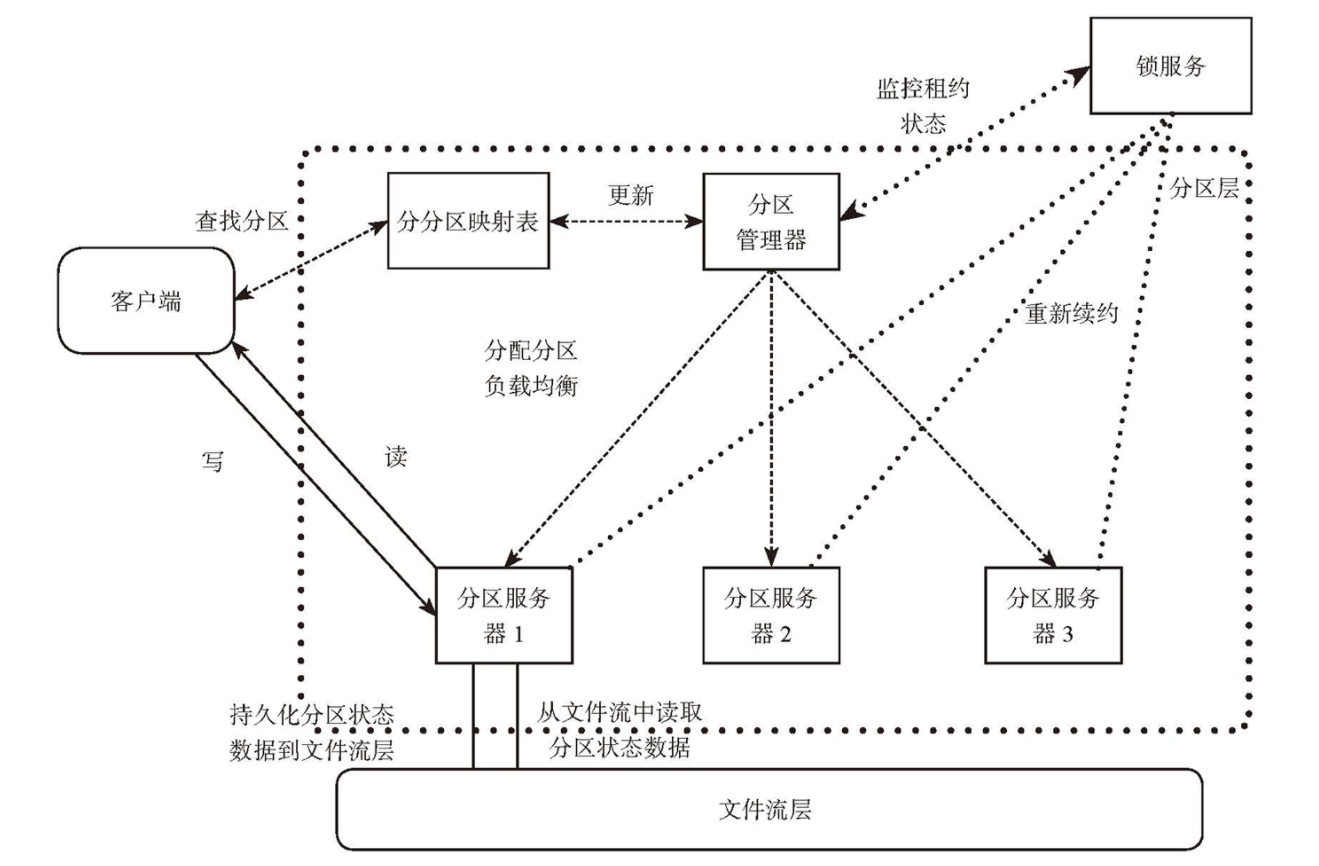
- 存储区内复制:在文件流层实现,同一个 extent(chunk)的多个副本之间的复制模式为强同步
- 跨存储区复制:服务分区层实现,通过后台线程异步复制,实现异地容灾
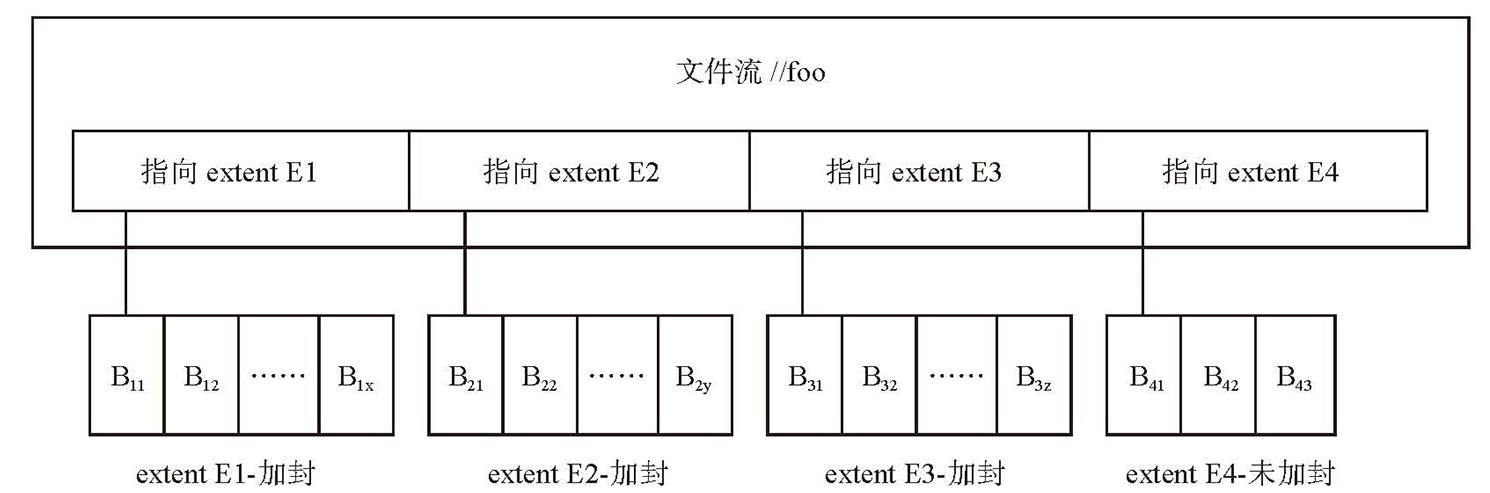
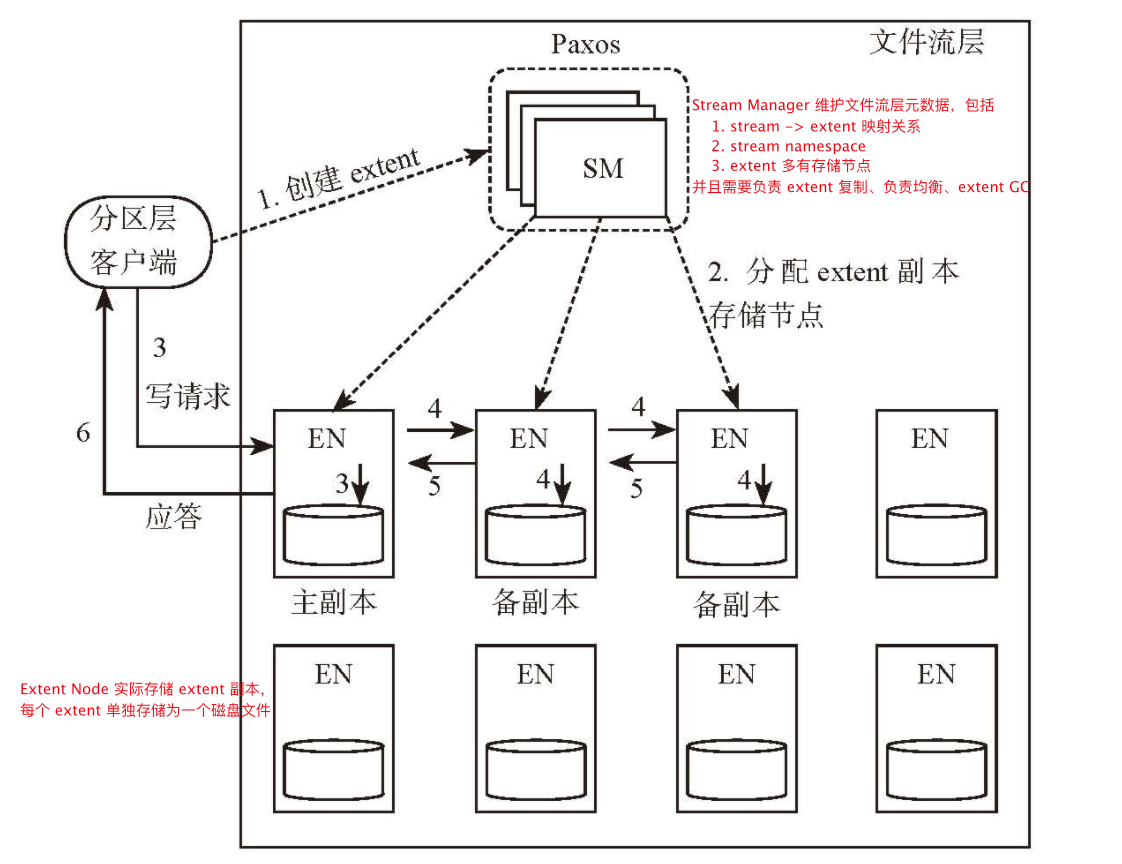
- 文件流层:文件流层中的文件称为流,每个流包含多个 extent,每个 extent 包含多个 block,如下图
- block 是数据读写的最小单位,每个 block 不超过 4MB,每个 block 维护 checksum
- extent 是文件流层数据复制、复制均衡的基本单位,默认每个 extent 保留三个副本
- stream 用于对外接口,每个 stream 在层级命名空间中有一个名字
- 文件流层架构
- 文件流层存储优化
- 如何保证磁盘调度公平性:如果存储节点上某个磁盘当前已发出请求的期望完成时间超过 100ms 或最近一段时间内某个请求的响应时间超过 200ms,避免新的 IO 请求调度到该磁盘
- 避免磁盘随机写:存储节点使用单独的日志盘顺序保存节点上所有 extent 的追加数据,追加分为两步
- 将待追加数据写入日志盘
- 将数据写入对应 extent 文件
- Reed-Solomon 编码降低存储空间
- 分区层架构