硬件基础
架构设计很重要的一点就是合理选择并且能够最大限度发挥底层硬件的价值
CPU 架构
SMP(Symmetric Multi-Processing) 对称多处理结构,处理器对等、无主从关系、扩展能力有限
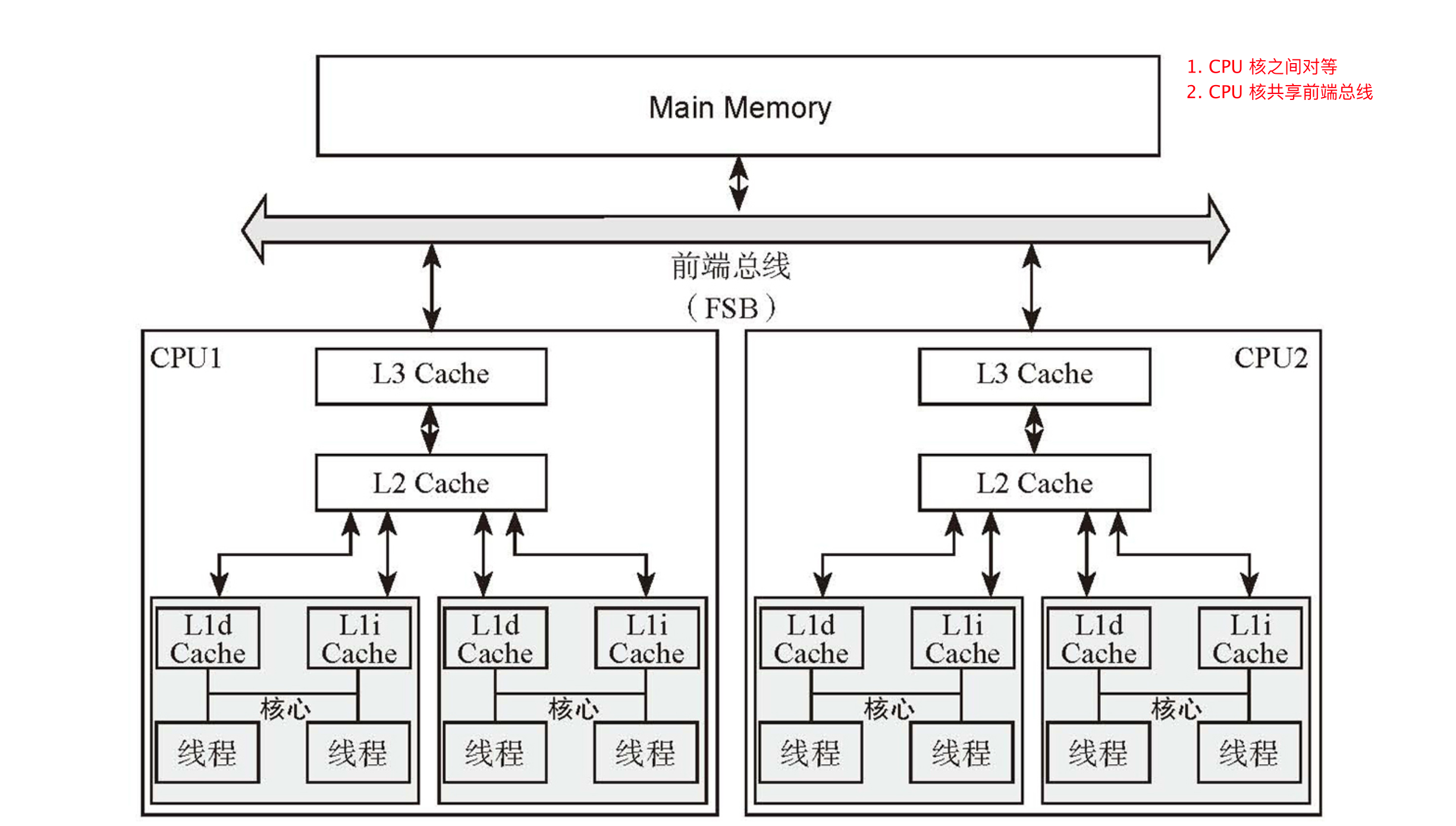
NUMA(Non-Uniform Memory Access) 非一致存储访问
- 多个 NUMA 节点,每个节点是一个 SMP 结构,
- 每个节点拥有独立的本地内存、IO 槽口
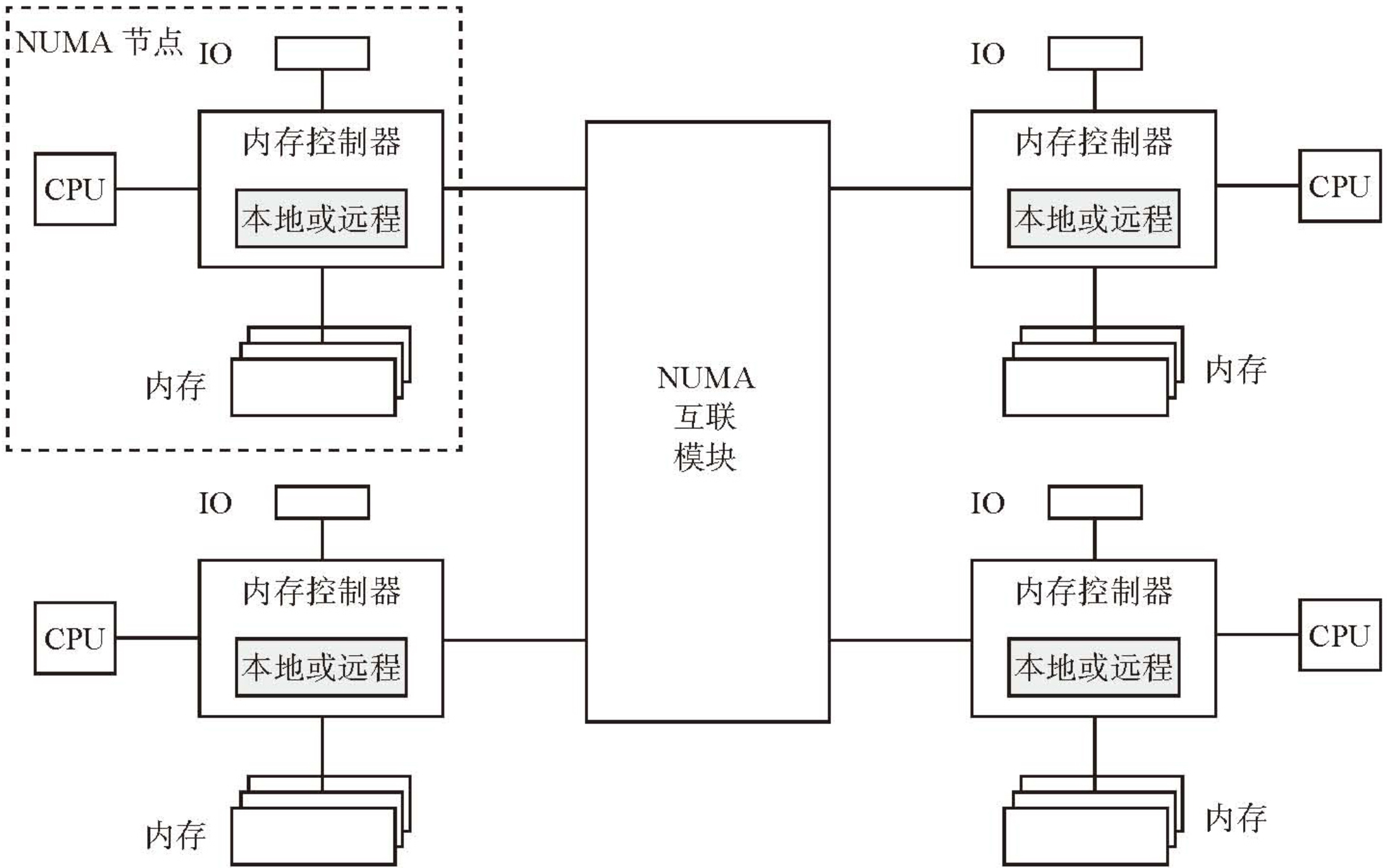
IO 总线
- 存储系统的性能瓶颈一般在 IO
- 存储系统的性能瓶颈一般在 IO
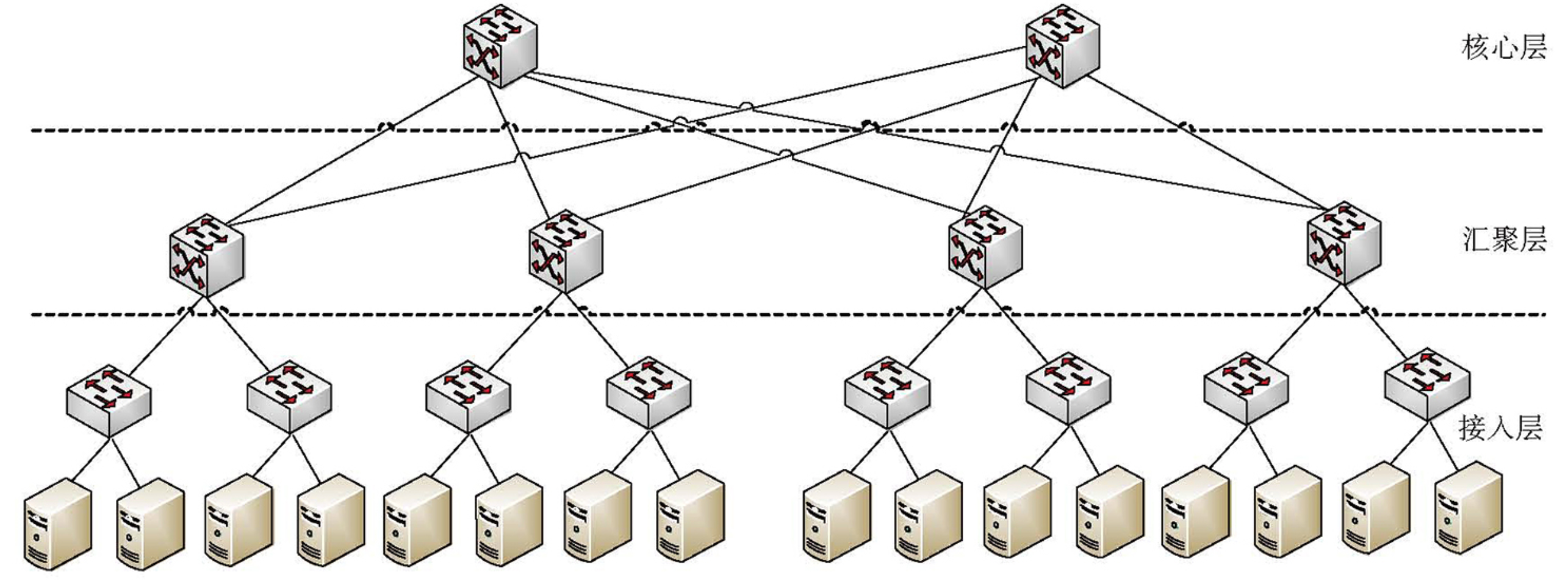
网络拓扑
- 思科经典三层架构:接入层、汇聚层、核心层
- 3 层带宽
- 接入层:48 个 1Gb 端口、4 个 10 Gb 端口
- 汇聚层:128 个 10Gb 端口
- 核心层:128 个 10Gb 端口
- 同一个接入层下的服务器之间带宽为 1 Gb
- 不通接入层下的服务器之间带宽小于 1 Gb

- 3 层带宽
- 三级 CLOS 网络
- 同一个集群内最多支持 20480 台服务器
- 同一个集群内的任何两台机器间有 1Gb 带宽
- 需要投入更多交换机,但设计时不需要考虑网络架构,方便将集群做成一个资源池
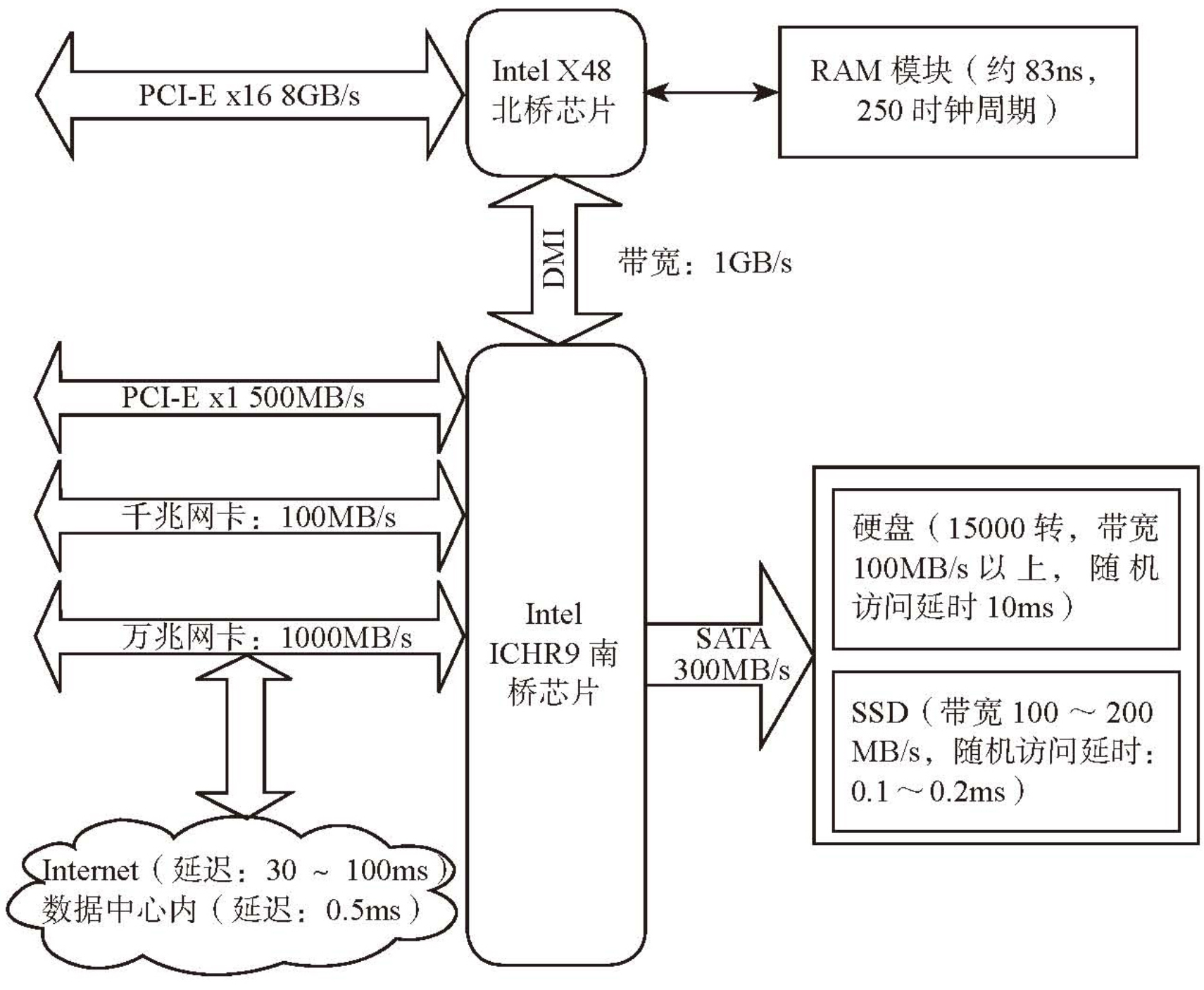
- 硬件性能参数

- 内存 & SSD & SATA 盘性能参数

- 思科经典三层架构:接入层、汇聚层、核心层
单机存储引擎
- 单机存储引擎是哈希表、B 树等数据结构在磁盘上的实现
- 存储引擎分类
- 哈希:支持增、删、改、随机读、不支持顺序扫描(hash 无序) 对应键值存储系统
- B 树:支持增、删、改、随机读、顺序扫描,对应关系数据库
- LSM 树:支持增、删、改、随机读、书按需扫描
- 表格存储系统 Google Bigtable、Facebook Cassandra
- KV 存储系统 LevelDB
哈希存储系统 Bitcask
- 只支持追加操作 Append Only
- 数据结构:key、value、key_size、value_size、timestamp、crc
- 内存:哈希表索引
key → file_id + value_pos + value_size - 磁盘:完整数据
- 写入:追加写 key-value 到磁盘 → 更新内存哈希表
- 读取:内存读索引 → 磁盘读 value
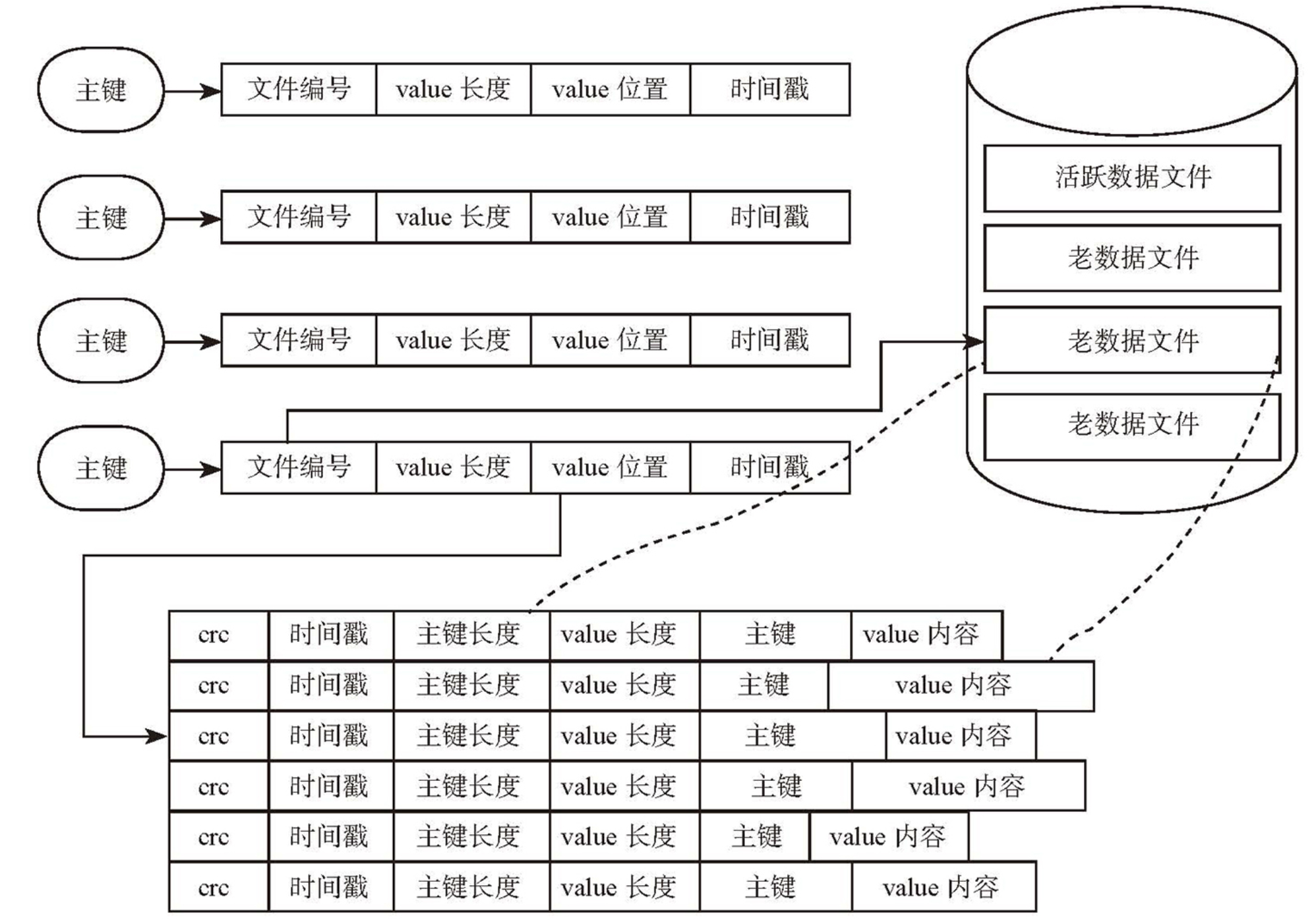
- 内存:哈希表索引
- 定期合并:需要定期进行 GC,只保留最新的 value
- GC 过程扫描所有的老数据文件,生成新数据文件
- 快速恢复
- 索引:通过磁盘上的索引文件(hint file)加速重建内存索引
B 树存储引擎
- 按页面(Page)组织数据,每个 Page 对应 B 树的一个节点,叶节点存数据,非叶节点存索引
- 数据结构如下(B+树根节点在内存中有缓存)
- 写流程:写 WAL 日志 → 写 B+ 树
- 读流程:读 B+ 树
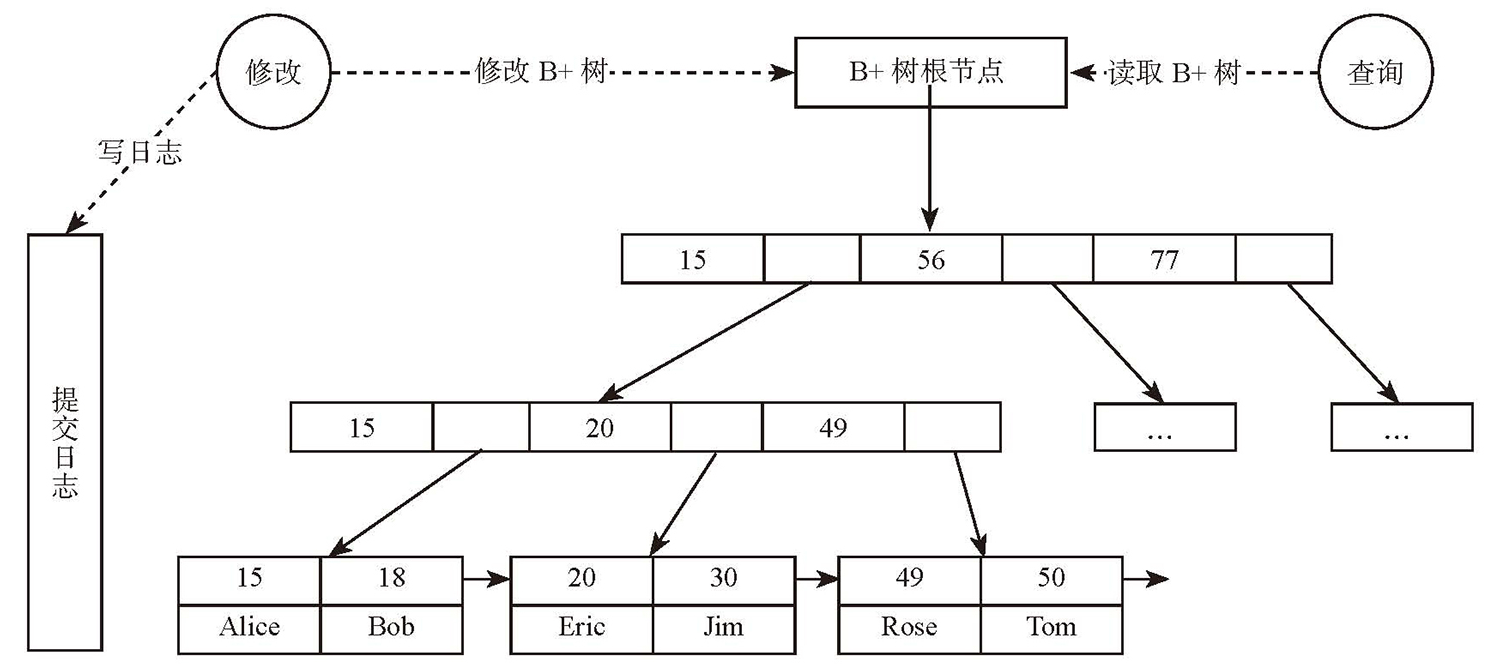
- 缓冲区管理
- LRU(Least Recently Used):每次淘汰最长时间没有读写过的元素
- 在全面表扫描时会把 LRU 全刷一遍,导致缓存命中率下降
- LIRS 两级 LRU,分为新子链表(new sublist)和老子链表(old sublist),先插入老子链表,元素在老子链表中停留的时间超过阈值后才加入新子链表(类似 JVM gc 分新生代、老生代)
- LRU(Least Recently Used):每次淘汰最长时间没有读写过的元素
LSM 树存储引擎

数据模型
- 文件:目录树模型,支持操作 (POSIX API)
- open/close
- read/write
- opendir/closedir
- readdir 遍历目录
- 关系:二维表模型,支持 SQL 操作
- SELECT
- INSERT
- UPDATE
- DELETE
- 键值:哈希表模型,支持操作层
- put
- get
- delete
- 表格:kv 操作 + scan
- 关系模型在大规模数据下面临的挑战
- 事务
- 多节点事务协调,如何在多节点都保证 ACID
- 如何保证两阶段提交协议的性能和故障容忍
- 联表:数据记录需要的属性从多张表查到
- 性能和数据库范式的(冗余)的权衡
- 性能
- B+ 树引擎本身的写性能瓶颈
- 扩展性问题
- 事务
- NoSQL 系统在面临的问题
- 缺少统一的标准,如 SQL 之于关系数据库
- 使用及运维复杂:系统多、适用场景不一样
事务与并发控制
- 隔离级别与对应的问题
- LU(Lost Update):后一个事务回滚了前一个事务的变更
- SLU(Second Lost Update):后一个事务提交覆盖了前一个事务的变更
- NRR: 同一数据项
- PR:同一个查询范围

并发控制
- Copy OnWrite
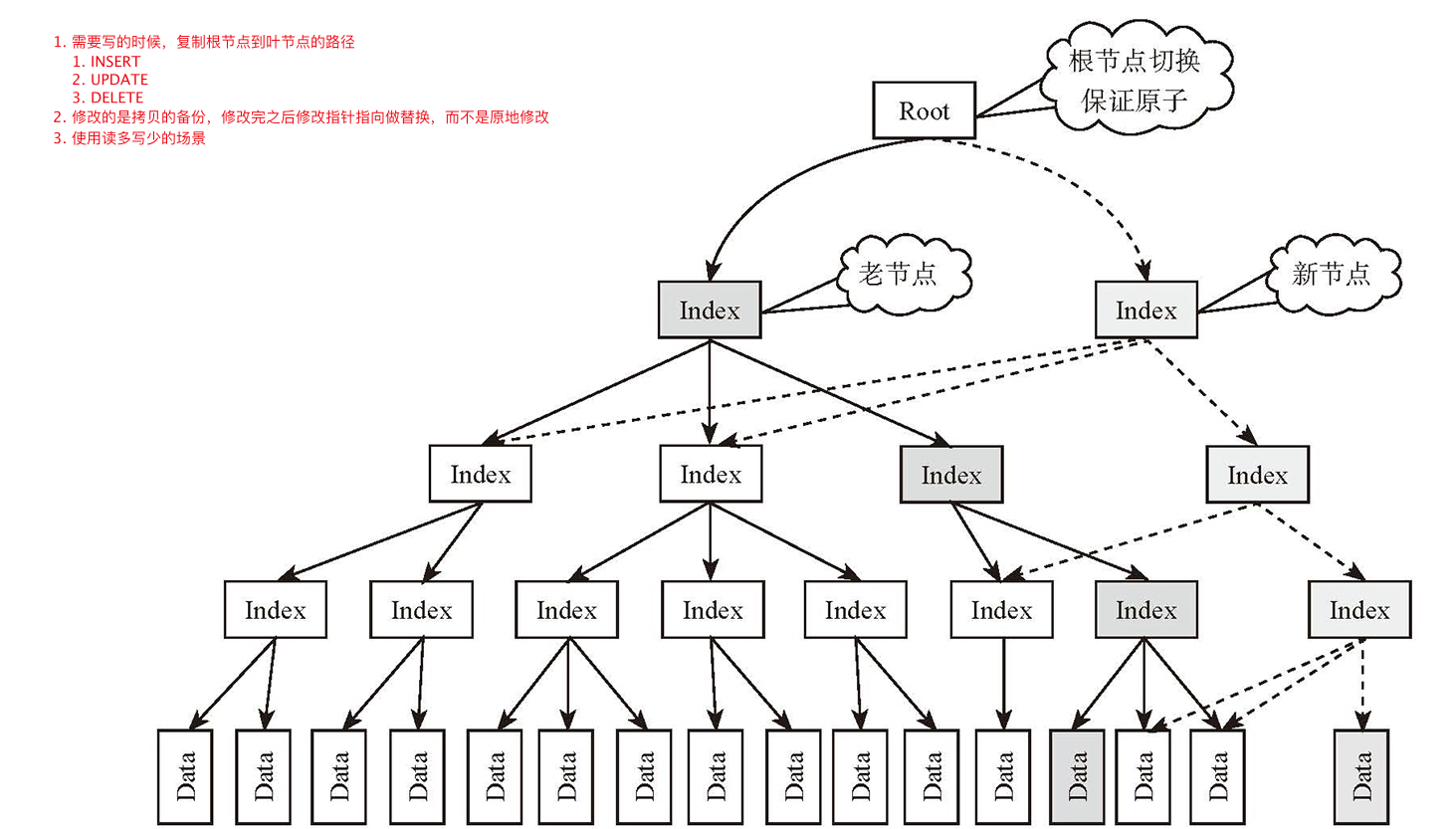
- MVCC
- 每条记录记两个版本号,一个生成版本,一个删除版本,版本号单调递增
- 记录更新版本号
- 插入时记录第一个版本号
- 删除时,为标记删除,即记录版本号
- 更新时,记录新的版本号
- 查询时对比查询版本号和更新版本号确定事务能看到哪个版本
操作日志
- 操作日志分类
- 操作日志 <table, record, rollback_value, commit_value>
- UNDO 日志 <table, record, rollback_value>
- REDO 日志 <table, record, commit_value>
- 优化手段
- 批量刷盘,减少 IO 次数
- checkpoint,减少重放时间

